
Processing multi-page documents using RPA and Amazon Textract
By organizing, analyzing, and extracting usable data from many documents, document processing keeps businesses going. To make wise decisions and manage their operations well, firms must properly handle bills, contracts, reports, and handwritten notes. This activity is difficult in the digital age due to too many documents, forms, inefficiencies, human errors, and scalability concerns. This blog discusses document handling issues and how Amazon Texatract will help.
🔺Challenges faced by RPA tools while handling multi-Page PDF
Handling multi-page documents using RPA tools presents several challenges. Leading RPA tools are designed to automate repetitive tasks, including document processing. However, the handling of multi-page documents can introduce complexities due to the following reasons:
- Complex Document Layouts: Multi-page PDFs have many layouts and formats. This diversity can include tables, graphics, footnotes, and parts that vary throughout pages. Without advanced OCR and document processing algorithms, RPA technologies may struggle to extract data from such complicated structures.
- Text Recognition Accuracy: RPA tools often extract PDF text using OCR. OCR accuracy is affected by PDF quality (scanned documents are especially difficult), font, and background graphics or watermarks. Data extraction problems can occur, especially from multi-page documents with inconsistent quality.
- Data Extraction from Tables: Tables are common in multi-page PDFs, especially in financial reports, invoices, and technical documents. RPA tools may find it challenging to correctly identify and extract table data due to complex layouts, spanning cells, and tables that continue across multiple pages.
- Handling Dynamic Content: Multi-page PDFs like reports and contracts may feature dynamic material that changes format. When they meet a different document structure than what they were programmed for, RPA solutions that are not equipped to handle variability require numerous additional, tailored steps to process the variations.
- Performance and Scalability: Processing massive volumes of multi-page PDFs takes time and resources. This may affect RPA solution speed and scalability, requiring improvements and more powerful hardware to manage huge workloads.
Even though most RPA systems have advanced automation, these issues can slow down multi-page documents. Document data is sorted, extracted, and verified using AI algorithms. These models may be less useful for multi-page publications’ complexity and variation. Amazon Textract can help our RPA bots process multi-page documents quickly and accurately.
💡 What is Amazon Textract?
Amazon Textract is a service that extracts text, handwriting, and data from scanned documents. It works effectively with multi-page PDFs and other files. Asynchronous paper reading and extraction are Textract’s strengths. It handles multi-page, complicated files well. Managing financial reports, forms, and bills requires it to recognize and extract data from tables and forms on several pages.
🟦 Leveraging the benefits of using Amazon Textract
- Amazon Textract can capture and extract text from documents with varied layouts, image quality, or complex structures. OCR and advanced machine learning are used.
- Its machine learning models evolve with time, improving paper processing.
Textract uses document patterns to organize page content and simplify data extraction. - Amazon Textract may adjust size based on user demands. This application automatically assigns resources for a few to millions of document processing projects.
- Textract’s integration with Amazon A2I enables manual examination of complex documents for extraction. This extracts even the toughest papers accurately.
- Amazon Textract extracts information from multi-page PDFs using advanced technologies and integration with AWS. Multiple automatic document processing difficulties are resolved.
✔️ Amazon Textract goes beyond OCR.
🟩 Textract addresses issues with multi-page manuscripts in the following ways:
- Advanced OCR and Text Analysis: Textract can extract text, forms, and tables from multi-page documents.
- Machine Learning Models: It employs machine learning to figure out how a document is put together, making it easier to obtain data from complex, multi-format documents.
- Contextual Data Extraction: Textract appropriately extracts and processes information from multi-page texts by understanding context and relationships between data elements.
Connecting Amazon Textract to any RPA bot improves document processing. Textract organizes multi-page publication data. RPA bot workflows automate business processes utilizing this data. This link lets organizations process complex documents faster and more accurately with less manual labor.
How much does Amazon Textract costs?
Amazon Textract offers pay-as-you-go pricing, so you pay only for actual usage. Billing is based on the number of pages processed by Textract. Having no upfront cost makes it very easy to get started.
Invoking Textract from RPA bot
Let’s take a look at some more detailed technical know-how as to how you can integrate Textract into your RPA bot. To process a multi-page document, we need to invoke Textract and process the data it returns. We can use Python to build this integration.
✔️ Here’s how it can be done:
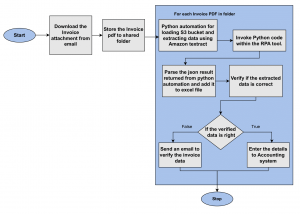
How to set Up Amazon Textract?
- The first step is to sign up for an AWS account if you don’t have one. You can access the Amazon Textract service through the console. You can manually upload documents and check how it works.
- Set up Python and the necessary packages
We will be integrating Textract using Python. Install Python 3.8 or higher on the machine that will run the RPA bot. Next, install the Boto3 package, which is the official AWS SDK for Python.
- Invoking Textract programmatically
Before you can invoke Textract programmatically, you will have to obtain the necessary credentials (Access Key ID and Secret Access Key) to authenticate your requests to AWS. Write a Python script that uses the Boto3 library to interact with Amazon Textract. This script should include functions to start text detection jobs, retrieve the results, and extract the desired data from the PDF documents.
- Set Up RPA project
Create a new RPA project/bot or open an existing one where you want to integrate the Python script for Amazon Textract.
- Use the Python activity
In your RPA bot workflow, use the Python” activity, if available, to invoke the Python script. This activity provides a container for running Python code within a bot workflow. If such an activity is not available, it should be possible to run the Python script via the command line.
- Pass input data and receive output
Pass the necessary input data, such as the PDF document or its location, to the Python script using the “Invoke Python Method” activity within the Python scope. Receive the output from the Python script, which should contain the extracted data from the PDF, and store it in RPA bot variables or process it further within your automation workflow.
- Error Handling and Logging
Implement error handling and logging mechanisms within your bot workflow to capture and manage any potential errors or exceptions that may occur during the integration with Amazon Textract.
💡Key Takeaway
Connecting Amazon Textract to any RPA solution improves your bot’s document handling. It can make processing multi-page documents easier and reduce processing expenses significantly.
🤝 Contact us at sales@valueglobal.net to learn more about how RPA and Amazon Textract can revolutionize your document handling processes. Schedule a consult with us to take the first step towards unlocking efficiency and innovation within your organization.